
More details on the app and method in Andersen and Zehner (2021) [OA]
First Steps
- download and install the app: see the Download Page
- start the app: enter shinyReCoR::recoApp() in your R(Studio) console
- the app’s window opens
Classify your Text Data: The Minimalist Approach
- Import your (CSV) data. Alternatively, if you just want to give it a try, press the Import Demo Data Set button.
- Choose the preprocessing you desire. Click Start Preprocessing.
- Choose a prebuilt corpus and corresponding semantic space in the table on the right by activating the checkbox in the first column. For the English demo data, choose Small Social Zoo, for the German demo data, Soziale Zootiere. Need more spaces? Go to SETUP & CORPUS and download additional prebuilt ones.
- Explore the responses’ tokens in the semantic space. Not required but beautiful.
- Press Compute Response Vectors in the Response Semantics tab.
- Choose a suitable number of clusters and press Build Cluster Model in order to identify response types in the response data.
- Press Start Cross-Validation for evaluating the agreement between the computer’s and the manual codes.
- Enjoy your classifier by exploring it. Enter some responses, see how they are classified, and where they are located in the semantic space.
Too Slow?
- If you select large corpora, all steps from the third one on will be slowed down.
- Consider enabling parallel processing in the SETUP & CORPUS tab.
- If the beautiful interactive 3d plots take too long on your machine, before starting the process, choose PCA instead of t-SNE as the dimensionality reduction technique.
But … That’s not All, Is It?
No, you’re right. The minimalist approach just goes straightforward through a scenic route, which provides you with diagnostic tools, project management, code label management, and lots more. Note that your work in the app will be stored once the app is closed and will be loaded when you return.
We will cover your curiosity about how to use the app in more detail with a video soon.
Prebuilt Corpora
The app comes with two small corpora; one for German and one for English. In the SETUP & CORPUS tab, however, you can download several more. And what if you want to use some fancy word2vec, GloVe model, or the like? Check out the following description.
Semantic spaces are matrices where each vector characterizes the semantics of a word. The meaning itself cannot be interpreted from the vector, but the semantic similarity to other words can. Therefore, words like ‘dog’ and ‘animal’ are semantically more similar to each other than the words ‘dog’ and ‘car.’ The similarity can be expressed quantitatively by calculating the cosine similarity of two-word vectors.
There are a variety of methods to build semantic spaces. While we are traditionalists and fancy Latent Semantic Analysis. which performs an SVD of a co-occurrence matrix, modern methods, such as word2vec or GloVe, typically work based on neural nets, where weights are trained iteratively. These set of weights then represent the semantics of a word in a vector.
Regardless of the utilized method, the representation of the semantics within those spaces is universal (i.e., vector space models). That characteristic allows for the blending of different methods. The space itself must only be stored as (R-specific) RDS-file in the package folder shinyReCoR (in your R library) within the subfolder corpus_vsm and have the ending _corpusspace.RDS. The space must also be defined as a matrix or data frame where the rows represent the words and the columns the dimensions, which can be any number (usually 300).
The dimensions must be numbered consecutively with vsm_d1, vsm_d2, vsm_d3, …, vsm_d300. The words must be given in the row names. Below is an illustration of the (semantic space) matrix in the R console.
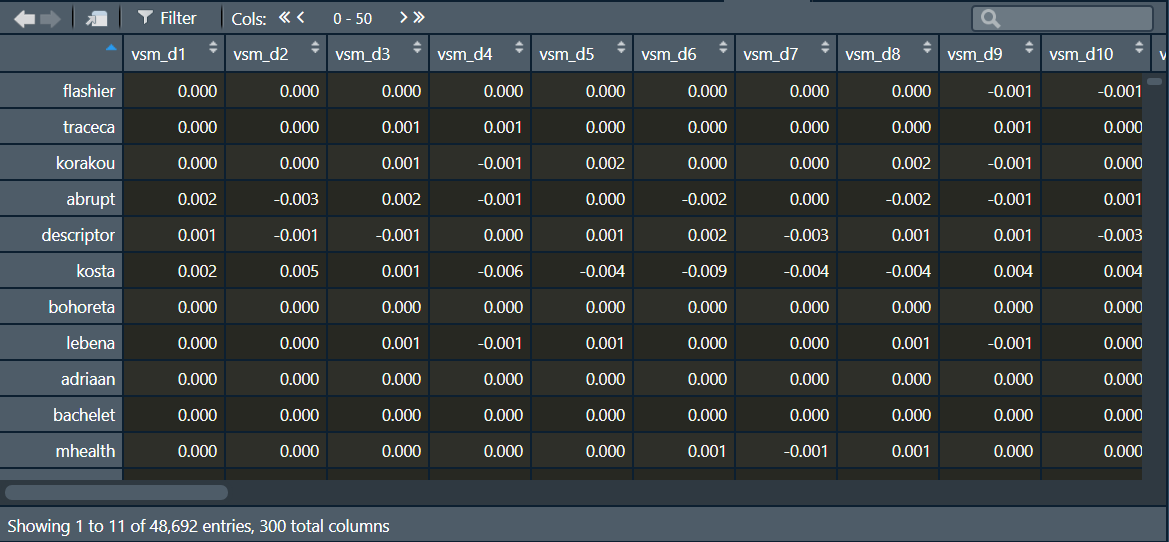
The word vector (row) represents the semantics of the word (row name) as a spatial arrangement over n dimensions (columns). If all requirements are fulfilled, the software recognizes the vector space, and you can select it in the tab 3 Text Corpus.
Where can you get such models? Well, models can be built directly by you, or you can use one of the many pre-trained models provided on the worldwide web. Since modern methods require enormous data for training a model and, consequently, longer computation times, the use of pre-trained models has become popular. A wide range of ready-made vector space models is offered on the web. Some examples are GloVe, word2vec, or wikipedia2vec.
What About Siaru?
Yes, ReCo’s methdology is largely scalable to other languages. We will soon cover more than only German and English. If you are impatient, you can try the following in order to check whether this works with your language. Configure the preprocessing to go without spelling correction and stemming. Change the list of stop words by resetting it and entering your own list. Then, manually add a prebuilt semantic space (aka word embedding) as described in the section above, and just give it a try. It might work.